
你爱听摇滚,他爱听抒情,“好听”有统一标准吗?
来源:IT之家 发布时间:2022-11-13 09:09 阅读量:19279
人类的听觉系统除了用于交流,识别和预警之外,还进化出了一种可能只有人类才拥有的高级智能,那就是音乐,比如独奏合唱,乐器独奏合奏等。
其中,歌唱是最容易也是最难的乐器因为谁都会唱,唱得好就是余音绕梁,三日不绝,反之,就可能是但他们粗糙而—刺耳,在我耳朵上篦
唱歌和说话的区别
人说话的时候,声音往往伴伴随着声带振动音调和频率在最自然的发声区域偶尔有人用腹式呼吸来增强声音的粗细,减轻声带的疲劳即使情绪波动会影响发音,一般变化也不会太大唱歌需要更多的技巧,和说话有明显的区别
第一,唱的音域千差万别比如俄罗斯男歌手维塔斯,从最低音到最高音能唱四个八度,非常厉害但我也可以
其次,在共鸣腔的使用上,唱歌和说话有很大的区别比如唱歌用的头部共鸣和鼻腔,后脑勺共鸣不一样,导致音色差别很大根据歌曲风格的不同,一般人常听的美声,喜欢把头腔听觉,身体感觉,语言共鸣放在后面
如果你注意看歌手唱歌,有些歌手在唱高音的时候会眨眨眼,皱皱鼻子,其实就是在寻找高音共鸣的位置。
对于歌曲表达的粗细,光靠头腔是不够的,因为会比较细,必须用胸共鸣来加强中低音域的共鸣。
如果想提高音域,还可以学习用面罩,咽部,封闭唱法来唱而低音,比如呼麦唱歌,需要输送空气到声带振动发声
第三,气息也是说话和唱歌区别更大的地方歌曲中有些歌词特别长,仅靠浅胸呼吸往往难以保持旋律的稳定和连续,需要使用胸式呼吸和更复杂的换气技巧
第四,和说话不一样,一般是平稳流畅的,一首歌的节奏变化很大,速度和急迫感可能会出现在一首歌里。
第五,对歌词的理解和情感的投入也会使唱和说产生显著的差异。
第六,连续阅读的问题中文歌词相对好一点,但是英文在唱功上明显很多关于唱歌和说话,人们可能还会有一种错觉,认为口吃的人唱歌不好但实际上,两者属于不同的发声机制说需要思考说什么,组织语言,说出来唱歌通常是一首音准,语速,音调都已经给定的歌人需要做的,就是在反复练习之后,重复这些内容所以,口吃的人可以通过学唱歌来尝试找到流利说话的信心
如何评价一首歌好不好。
对大多数人来说,唱歌是放松心情的方式之一当你听到一首喜欢的歌,你就学会唱它但是好吗很多人不太了解
什么样的歌可以被定义为好歌音乐好不好的定义里有一个和频率f有关的一般规律
这是日本著名物理学家李广1965年在《应用物理学会会刊》上发表的文章《生物信息与1/f涨落》中提出的1/f涨落原理或者说涨落是指一个物理量在宏观平均值附近的随机变化,其原理适用于很多领域
就音乐而言,1/f表示旋律可以局部无序,而在宏观上有一定的相关性,可以让人感受到舒适和谐的波动市面上很多抒情歌曲都是符合1/f波动原理的歌曲,所以大家都喜欢听
对于其他形式的音乐风格,如摇滚,说唱等,是因为它所包含的节奏可以帮助人们发泄和表达自己的感情
更有甚者,还有完全背离1/f涨落原理的歌曲,比如实验歌曲《烟花》,几乎接近噪音。
为了帮助评价音乐好不好,科学家们还提出了一些心理声学的定性和定量指标,如基于粗糙度,锐度,波动和音高等声学特征组合的烦恼度和感知快感等复合声学指标。
但无论如何约定,音乐风格的多样性,个性化色彩的丰富性,对声音的感知仍然是以个人的主观感受来评价的,大众认同的东西不一定能用来刻画小众群体的审美观点。
对于唱歌,有人喜欢粗犷低沉,有人喜欢清澈如水,有人喜欢响亮,有人喜欢委婉。
对于歌曲,有人喜欢奇奇怪怪的,有人喜欢平淡的叙述,有人喜欢口水歌,有人喜欢春雪。
音乐风格的多样性和个性化色彩的丰富性,很难真正形成统一的客观标准来评判。
歌曲/歌唱的相关应用
虽然对歌曲/唱腔的分析显然比简单的语音识别更加复杂和困难,但在人工智能领域仍然有一些相关的应用。
列举几个比较有价值的应用第一,歌曲哼唱识别,这是目前大部分提供音乐的平台都有或者正在尝试做的功能它的任务是根据本地片段的旋律识别可能的曲调困难在于不是每个人都能准确地哼出旋律大多数人这样找歌是因为不记得歌名,或者只是一个遥远的旋律记忆其次,发音频率,声调,吐字,原唱都有一定的差异因此,哼唱识别的任务就是从不准确的哼唱中找到有效的候选集
除了哼唱,另一个重要的应用是自动调音一是因为很少有人有绝对音高的能力,即使经过专业训练,可能还是不稳定第二,大部分人的语调和稳定性都有问题而且喜欢唱歌的人也很多因此,无论是专业歌手还是业余爱好者,自动调音都有很大的应用市场但是,由于音乐风格千变万化,需要学习和增强每个人独特的辨识度和个性化的音色,显然很难用人工智能技术来构造一个自动化的调音师
此外,音乐与人声的分离也是一个极其重要的研究方向人类在这方面的能力非常强,在非常嘈杂的环境中也能很容易地选择自己的声音来听1953年,Cherry将这种由人类听觉注意力引起的现象称为鸡尾酒会效应
虽然这一现象已经被发现近半个世纪,但人工智能仍然很难达到与人类相似的识别能力因为麦克风获得的音频信号一般是多个声源混合的一维音频信号,所以分离原始的多个信号源会是一个一对多的病态问题,没有唯一的解
事实上,人类听了录音后,是无法获得鸡尾酒会效果的。
为解决这一问题,人工智能领域通常假设这些信息源相互独立,不符合前面提到的高斯分布,输出结果是这些信息源的加权组合信息源分离,也称为盲源分离早期的方法是在机器学习和模式识别领域使用独立分量分析的技术或其改进版本,但这种方法的缺点是收敛速度慢,难以获得唯一解
特征融合后,用一个考虑时间变化的长短期记忆深度模型来描述音视频的时序特征最后,每个扬声器使用两种不同的解码系统来分离音频和视频模型达到了目前最好的效果,离模拟人类的鸡尾酒会效果更近了一步但仍有不足之处,主要表现在两个方面首先,我们需要视频的帮助其次,本研究没有涉及到歌唱与乐器分离这一更为困难的问题
输入视频帧和音频,
处理思路:分别提取视频和音频特征,分离音视频源,
为每个扬声器输出干净的音频。
当然,基于人工智能的音乐分析还有很多其他有趣的应用,比如计算机作曲/写歌词,设计一个像洛天依一样的唱歌机器人等等
但总的来说,人类作家写出的歌词和旋律的意境往往具有更好的整体性和更强的逻辑性而计算机模拟目前只能做到局部近似,要把握全局和整体情绪还有很长的路要走或许现阶段考虑与人混合智能处理是一个很好的尝试
书籍介绍
张俊平,复旦大学计算机科学与技术学院教授,博士生导师主要研究方向为人工智能,机器学习,图像处理,生物认证和智能交通2007年9月至2008年3月以访问学者身份访问加州大学圣地亚哥分校,2014年8月至2015年8月被宾夕法尼亚州立大学聘为研究助理一年先后主持国家自然科学基金,863项目,浦江人才计划项目三项目前主持科技部2018年重点专项人—机器人智能融合技术子项目,国家自然科学基金面上项目中国自动化学会混合智能专业委员会副主任,中国计算机联合会人工智能专业委员会委员,中国人工智能学会机器学习专业委员会常委发表人工智能相关高质量论文100余篇包括IEEE TPAMI,TNNLS,ToC,TAC,TITS,TVCG等国际期刊和ICML,AAAI,ECCV等国际会议
看原点的小红书!
郑重声明:此文内容为本网站转载企业宣传资讯,目的在于传播更多信息,与本站立场无关。仅供读者参考,并请自行核实相关内容。
站点精选
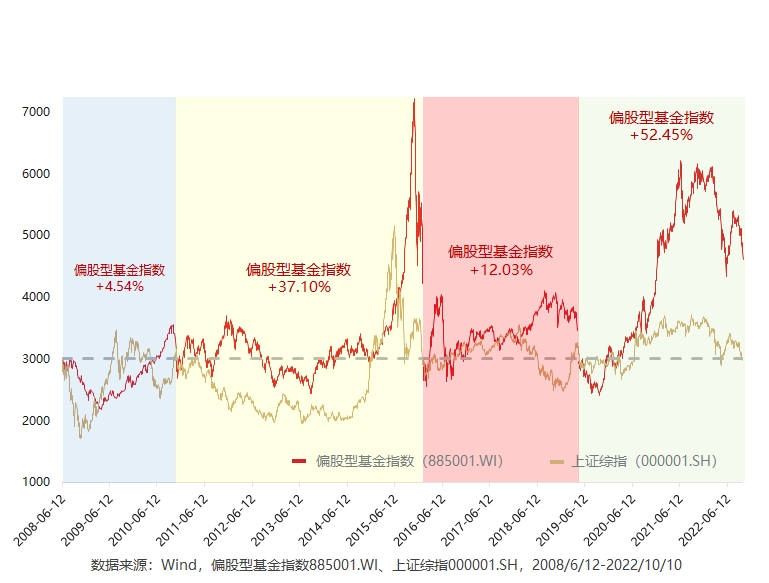
峰回路转之后,市场再次下探关键点但是,我们在探究和观察的时候,可能点是一样的,但是这段时间基金市场的整体表现是不一样的:虽然指数没有额外的表现,但是偏股型基金在...
- ROYCE巧克力是哪国的2022-11-12
- 腊八节上供吗2022-11-12
- 亚朵登陆纳斯达克股价首日涨17.09%2022-11-12
- BDI创7个月以来新低航运超级周期要结束了吗?2022-11-12
- 江苏银行数智化转型新成果“苏银链3.0”全新启航2022-11-12

